注意力架构#
GQA 家族#
MHA (Multi-Head Attention, 多头注意力)是最早在 Transformer 模型中提出的标准注意力机制。它没有让模型用一套注意力权重去学习所有信息, 而是将输入拆分成多个头(Head)。每个头独立学习输入序列在不同子空间中的表示,关注不同的信息(比如,一个头可能关注句法关系,另一个头关注语义 相似性)。最后,将所有头的输出拼接起来,通过一个线性层进行融合。MHA每个头都拥有自己独立的查询(Query, Q)、键(Key, K)和值(Value, V) 投影权重。如果有 h 个头,就有 h 套独立的 Q, K, V 权重。 其优点是强大的表示学习能力,效果好。缺点也很明显,计算量和内存占用最大。在模型 推理(生成)时,需要缓存每一层的 K 和 V,这个 K/V 缓存会非常大,成为推理速度的瓶颈。
为了解决 MHA 的推理效率问题而提出的优化,MQA (Multi-Query Attention, 多查询注意力)被提出。MQA 依然保留了多个查询头(Query Heads), 让模型能从不同角度去“查询”信息。但它让所有的查询头共享同一套键(Key)和值(Value)的投影权重和缓存。如果h 个 Q 头,但只有 1 个 K 头和 1 个 V 头。MQA极大地减小了 K/V 缓存的大小,显著提升了推理速度和吞吐量,同时对模型性能的负面影响相对较小。然而,相比 MHA,由于所有头共享 K/V, 可能会损失一些模型的表示能力,导致性能有轻微下降。
GQA 是 MHA 和 MQA 之间的一种折中方案,旨在平衡性能和效率。它将查询头(Query Heads)分成若干组,组内的查询头共享同一套键(Key)和值(Value) 投影。 假设有 h 个 Q 头,将它们分成 g 组,那么就有 g 个 K/V 头。每 h/g 个 Q 头共享一个 K/V 头。在推理效率上远超 MHA,在模型性能上通常优于 MQA。它提供了一个灵活的旋钮,可以通过调整组的数量 g 来权衡效率和效果。实现比 MQA 稍复杂,但带来的性能提升通常是值得的。
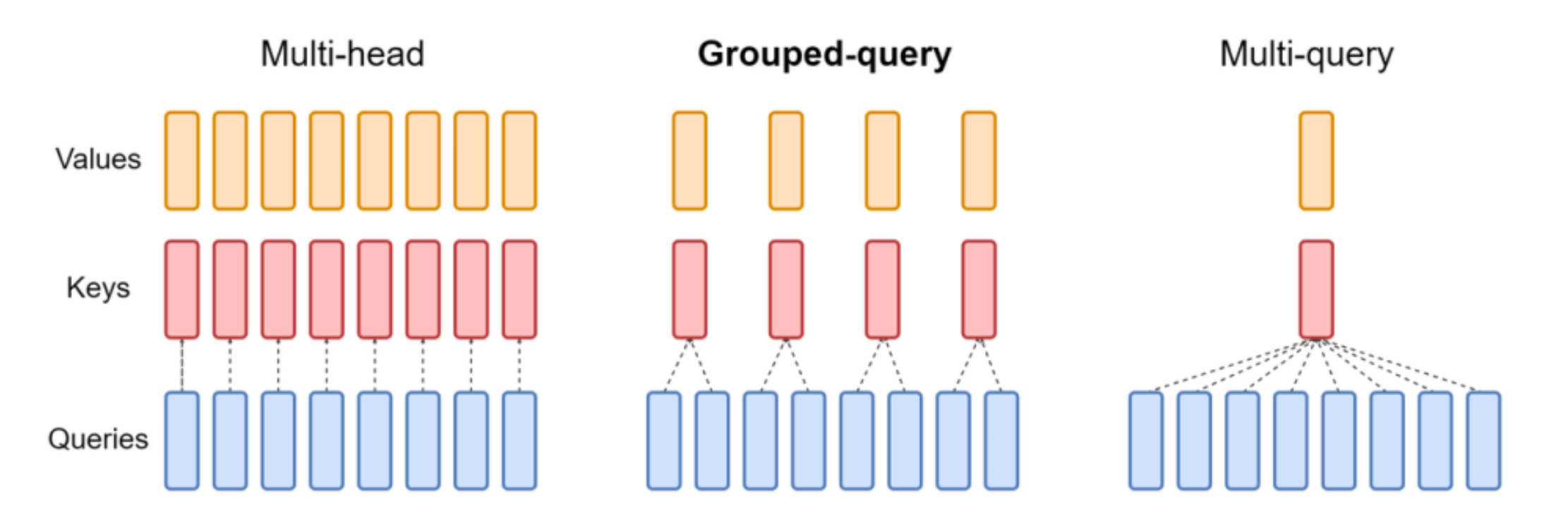
为了简化,我们将MHA/MQA/GQA简化为GQA家族,即CT-HPKV认为MHA/MQA是GQA的特殊形式。GQA家族的模型在KV Cache的格式和管理上具有相同的形式,CT-HPKV 卸载方案对GQA家族模型均进行了全面支持。使用vLLM/SGLang启用CT-HPKV进行MHA/MQA/GQA模型部署时,没有额外的配置,CT-HPKV会自动识别模型的注意力架构特性, 启用对应的KV Cache卸载侧策略。MHA架构的模型包含早期的LLama2等, 现在大部分大模型的注意力部分基本都是GQA架构, MQA架构由于精度较差,基本被弃用, CT-HPKV理论上也是支持的。
MLA#
MLA(Multi-Head Latent Attention)由深度求索公司从DeepSeek-v2模型中提出,其注意力计算方式相比传统的多头注意力有了较大的变化。注意力架构的变化 也导致了其KV Cache的结构与Layout与传统多头注意力不同。比如, MLA中KV Cache分为RoPE和NoPE两部分。SGLang将RoPE和NoPE两部分KV Cache保存在了一 起,而在vLLM中却将两者分离, SGLang NPU的支持又做了特殊处理。此外,在MLA架构中,不同于GQA家族,每个TP Group纵向切分总的KV Head数量均分KV Cache 容量,MLA模型在TP Group内持有相同的KV Cache内容, CT-HPKV在进行KV卸载时也需要考虑以上各种特性之间的差异, 并且均作出了较好的支持。
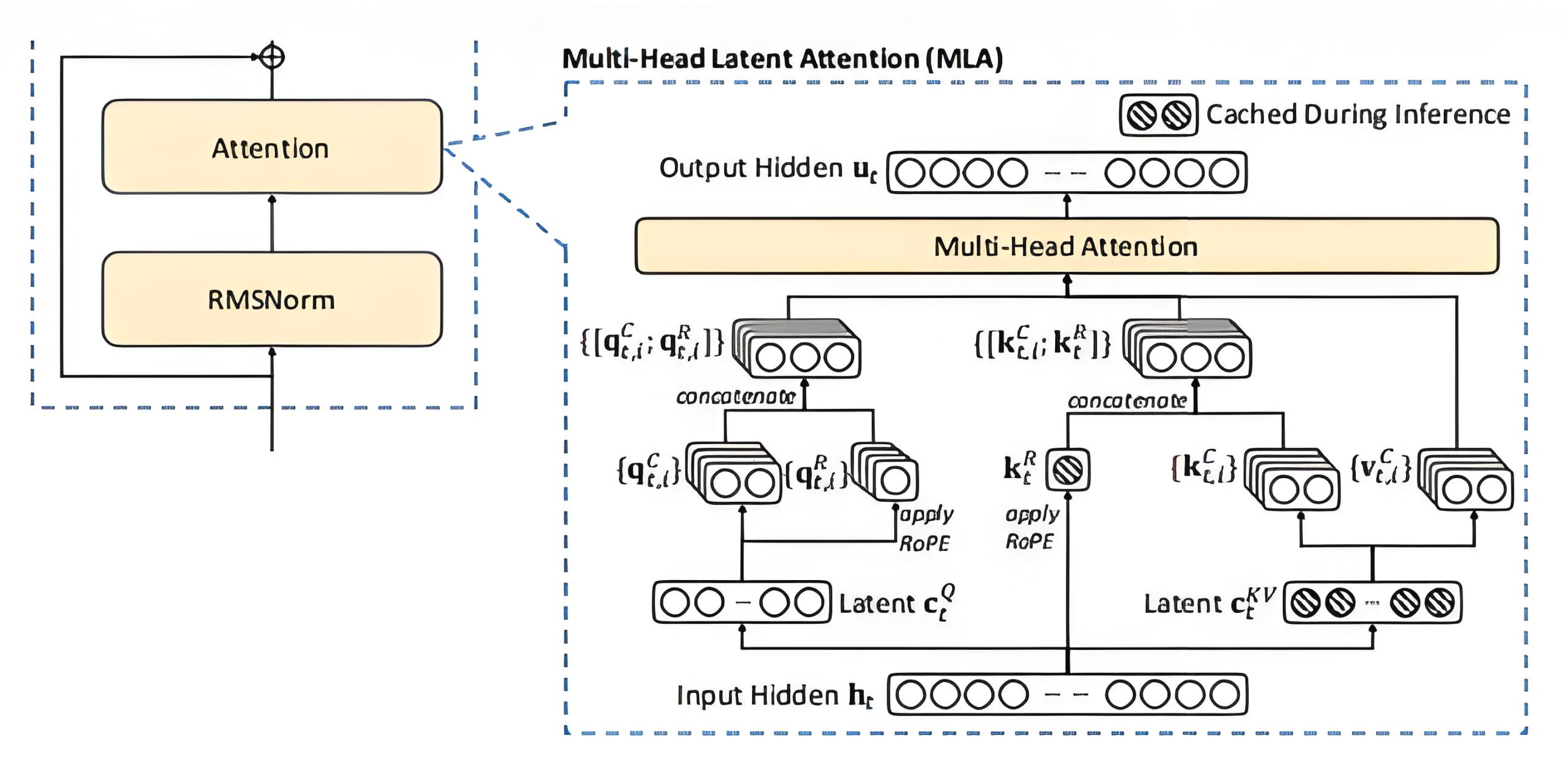
为了快速体验,我们可以选择模型参数叫较小的 deepseek-ai/DeepSeek-V2-Lite-Chat 模型为例,验证CT-HPKV对MLA的支持情况:
# 配置vLLM启用CT-HPKV
(base) hpkv@ctyunos:~$ export VLLM_ENABLE_HPKV=1
# 配置使用的内存池大小 (8G大小)
(base) hpkv@ctyunos:~$ export HPKV_KV_MEM_POOL_SIZE=8g
# 配置共享内存文件路径
(base) hpkv@ctyunos:~$ export HPKV_SHARE_MEM_FILE_PATH="/mnt/hpkv"
# 配置KV Cache文件存储路径
(base) hpkv@ctyunos:~$ export HPKV_KV_STORAGE_PATH="/mnt/hpkv/storage"
# 启动vLLM
(base) hpkv@ctyunos:~$ vllm serve /mnt/models/deepseek-ai/DeepSeek-V2-Lite-Chat \
--host 0.0.0.0 --port 8505 --trust-remote-code \
--served-model-name deepseek-v2-lite --block-size 64 \
--max-num-batched-tokens 8192 \
--gpu-memory-utilization 0.8 \
--enable-prefix-caching \
--kv-transfer-config '{"kv_connector":"HpkvConnectorV1", "kv_role":"kv_both"}' \
--disable-log-requests
MoE#
MOE 架构的基本思想是在传统Transformer模型中,将每个前馈网络(FFN)层替换为一个 MOE 层。一个MOE层通常由两个关键部分组成:
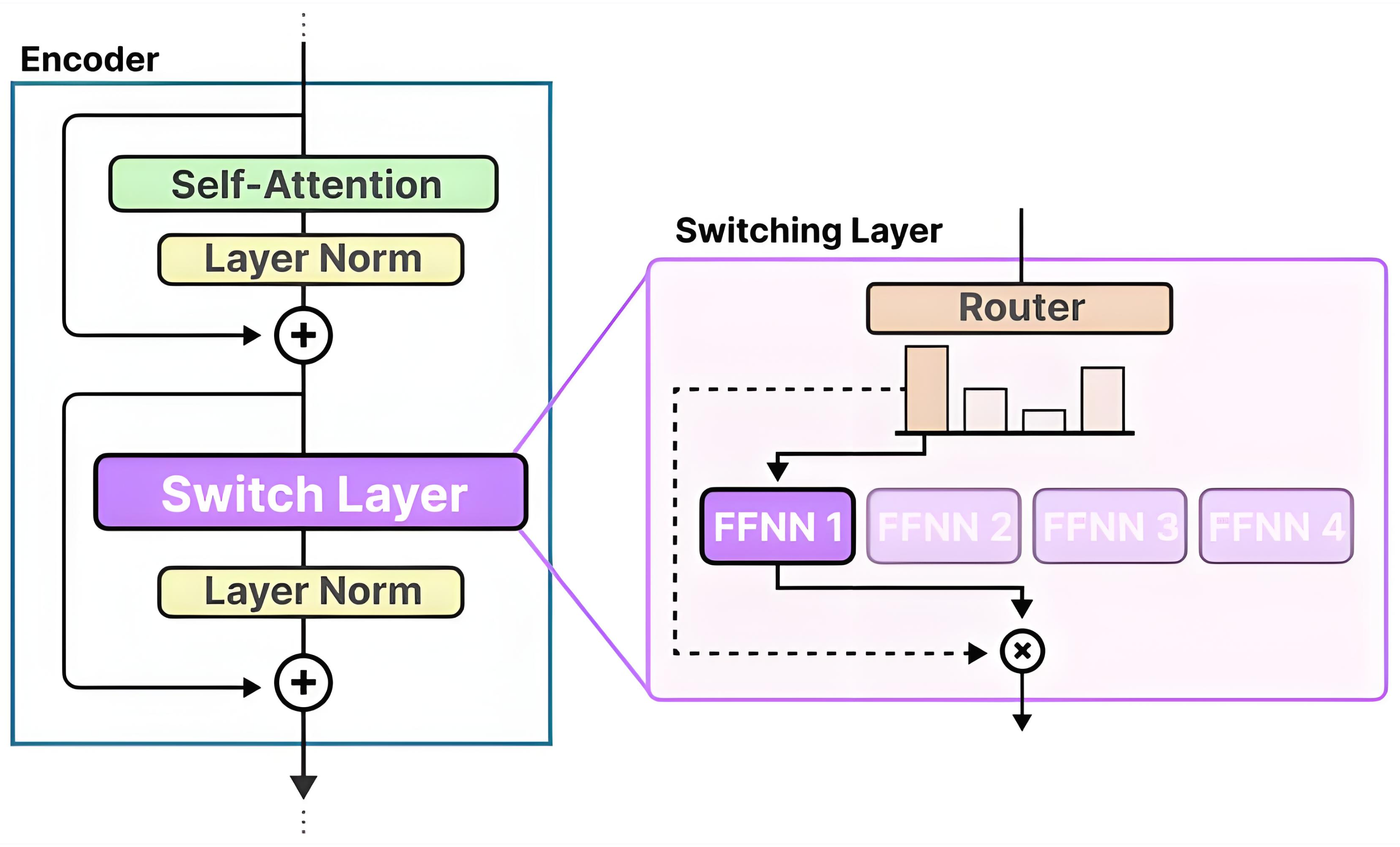
专家网络
每个专家是一个独立的子网络(通常是 FFN),在实际计算中只有部分专家会被激活参与处理。通过让多个专家分担不同数据子集的计算,模型在 预训练时可以以较低的计算开销获得大参数量带来的表示能力。
门控网络
负责根据输入词元的特征动态选择激活哪些专家,一般采用一个带 softmax 的简单前馈网络来计算每个专家的权重。经过训练后,门控网络会逐 步学会将相似的输入路由到表现更好的专家。在 DeepSeek‑v3等MOE大模型中,正是通过这种将 FFN 层替换为 MOE 层的设计,模型在拥有海量 参数的同时,其实际计算量却与传统稠密模型相当,从而实现了高效预训练和快速推理。
实际上,KV Cache是有注意力部分产生,跟FFN部分没有关系,无论是原有的简单FFN, 还是后来以LLama3为代表的带门控的FFN,以及后来的大 规模稀疏模型,其不会影响KV Cache计算和存储的逻辑。因此,CT-HPKV重点关注对应的注意力架构。
Mamba#
重要
2026.06.30 即将发布;
线性注意力#
重要
2026.06.30 即将发布;
稀疏注意力#
重要
2026.06.30 即将发布;