多级缓存#
层级缓存#
当前主流的LLM是Decoder-only架构,其核心是堆叠的解码器层,每一层都包含多头注意力机制(Multi-head Attention)和前馈网 络(Feed-Forward Network)。 其中,大部分模型的知识存储在前馈网络中。由于LLM是自回归的(autoregressive),即逐词生成, 后一个词的生成依赖于前面所有的词。 为了避免在生成每个新词时都重复计算整个序列,可以将历史词向量的键(Key)和值(Value)矩 阵缓存起来,这就是KV缓存。 这样,系统只需计算最新词的查询(Query),并结合缓存中的K和V值,即可高效生成下一个词。
更进一步,在系统固定提示词和多轮对话场景下,推理引擎可能处理大量重复的提示词序列、因此,推理引擎侧提供了Prefix Cache能力 实现KV Cache跨请求复用的能力。更细节的,SLGang提出了RadixTree可以实现词元级别的匹配和复用能力。然而,受限于AI芯片缓存 容量的限制,缓存的KV Cache数据很快可能被驱逐,从而导致KV Cache的命中率下降。
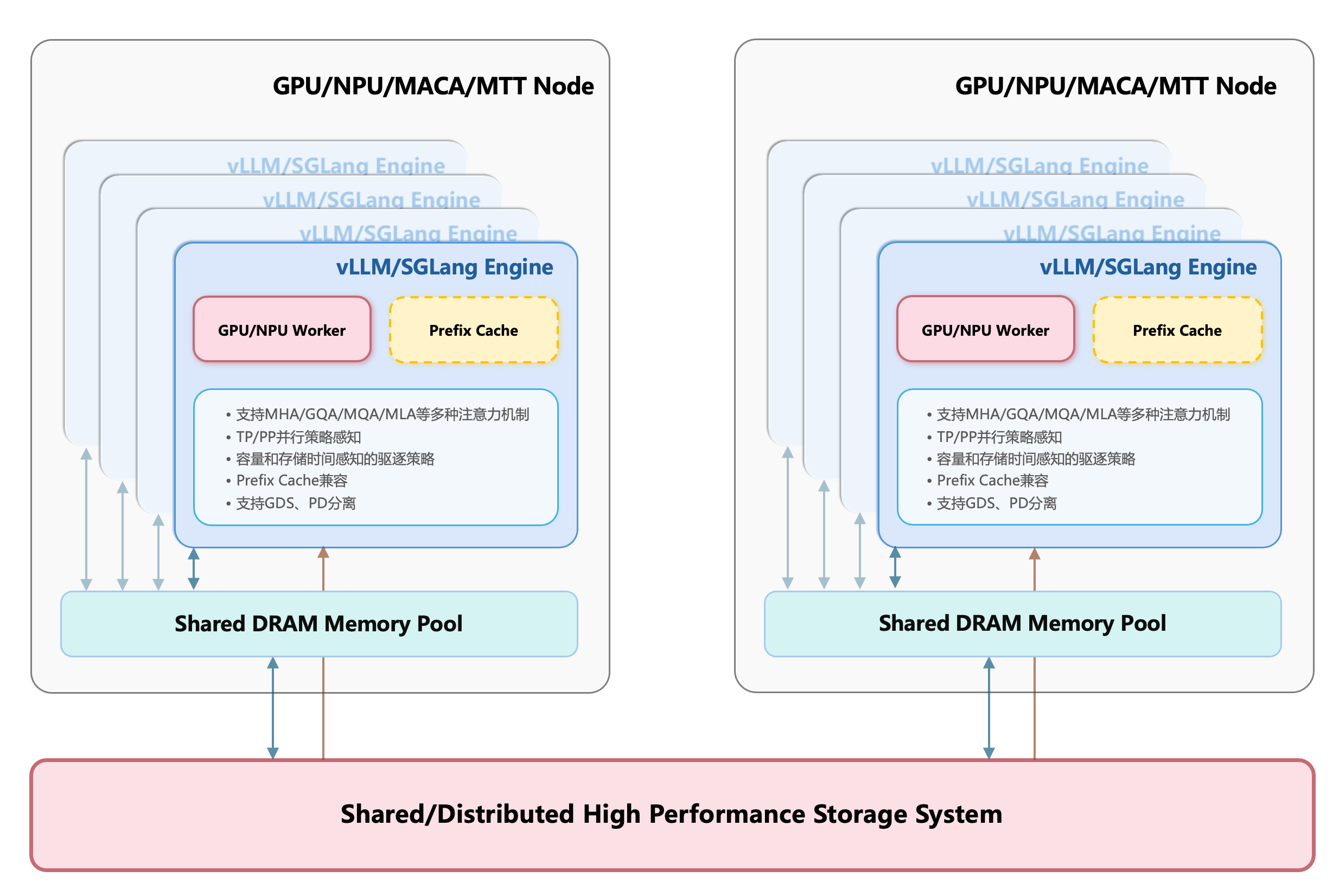
CT-HPKV则尝试将Prefix Cache能力扩展到GPU显存外,典型的如内存空间及本地和共享的高性能存储设备, 并且用户可选择地启用显 存、显存+内存、显存+内存+本地存储、显存+内存+共享存储等缓存模式。在实际推理请求到来时,CT-HPKV智能地从上往下进行匹配,在 设置的条件限制下,尽可能从缓存中复用数据,实现以存代算提升推理效率。
显存
芯片显存拥有大带宽,通常能达到几百GB/s到几TB/s, 最适合存放KV Cache数据。因此,在模型服务化部署中,尽可能分配多的显存空间
给到KV Cache。在推理引擎服务化过程中,经常可以将 gpu-memory-utilization 设置到 [0.85, 0.95] 之间。然而,
受到显存容量的限制,新的推理请求到达时,在KV Cache容量不足时,引擎不得不采取某种策略(LRU等)将过期的KV Cache数据清除,这
样,即使后来可能接收到之前处理过的重复率较高的请求,也不得不重新计算Prefill计算。
内存
相比显存来讲,内容通常拥有更大的容量,典型的服务器上都配置了以TB为单位的内存容量,使用内存扩展显存以支持KV Cache复用是很自 然的想法。不幸的是,内存通常拥有比显存低得多的带宽,且与AI芯片之间通过PCIe连接, 典型的PCIe Gen4.0 x16 和 PCIe Gen5.0 x16单向带宽理论分支仅有32GB/s 和 64GB/s。因此,内存扩展显存以支持KV Cache复用通常会带来额外的延迟。
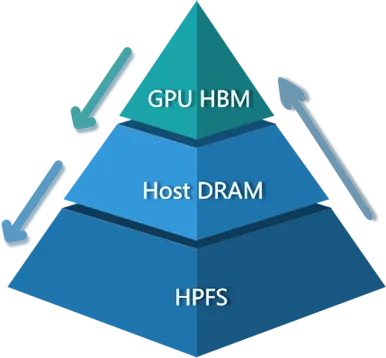
CT-HPKV在设计上考虑了这些问题,因此引入了低层级KV Cache复用的词元阈值。CT-HPKV认为,低层级的KV Cache由于传输延时和速率低
的原因,只有保证在一定命中阈值时才从低层级存储系统加载对应的KV Cache数据,否则直接考虑进行重算。在CT-HPKV中,引用了配置项来
实现该阈值的控制。在vLLM中为 VLLM_HPKV_TOKEN_THRESHOLD ,在SGLang中为 SGLANG_HPKV_TOKEN_THRESHOLD,默认
值均为1024, 用户可以在推理服务启动时根据需求进行修改。
存储
如果以传统通算的直觉,将KV Cache认为是普通的日志或业务逻辑的缓存数据,那么大模型推理的KV Cache的大小可能超乎想象。我们以参数
不算太大的 Qwen/Qwen3-32B 模型为例,该模型总共64层,每层8个KV头,头大小为128。假设推理时使用 bfloat16 作为KV缓
存的精度,对于一个长度为8K的请求,其对应的KV Cache大小为:128 * 8 * 2 * 2 * 64 * 8192 / 1024 ** 3 = 2GB, 对于一个配
备1T内存的服务器来讲,即使将全部内存空间用于扩展显存来存储KV Cache数据,也只能同时容纳几百条长请求的缓存。在企业级的MaaS场景
下,需要将KV Cache复用能力进一步扩展到更大容量的高性能存储。
本地存储
个人和小规模企业容易获得一定容量的高性能本地存储,如SSD等,通常可以达到TB级别,在拥有较高IO带宽的同时,一定程度上可以进一 步扩展内存作为KV Cache缓存的能力。
共享存储
大型企业或模型服务提供商拥有自研或购买的商业高性能共享存储,其容量可以达到几十TB甚至PB级别,能够极大扩展KV Cache存储容量, 进一步提升KV Cache复用能力。
多级融合#
CT-HPKV对KV Cache的匹配并不完全独立。事实上,CT-HPKV会从上到下,依次匹配。详细来说,先从带宽更高的显存空间进行匹配,计算出能够 匹配命中KV Cache的词元数量,然后再尝试从速度较低的内存系统中匹配,并计算出能够匹配的词元数量。最后,再尝试从存储系统进行匹配,并计 算出能够匹配的词元数量。各级匹配KV Cache的词元数量如果收益优于完全重算的代价,则异步从低层级存储系统拉取对应的KV Cache数据到显存 中,并返回给上层。因此,某一次KV Cache数据的匹配,可能同时来自显存、内存和存储系统的混合匹配,而非独立。