CT-HPKV中文文档#
备注
CT-HPKV正在飞速开发与迭代中,因此CT-HPKV中文文档也正在更新与完善中,部分章节可能不完善,敬请期待后续更新。
概述#
随着Agentic AI持续深化,长上下文、多轮对话、海量请求等场景加快发展,推理系统对底层资源调度和缓存管理提出了更高要求。输入更长、交互更频繁、 请求更多,都会带来KV Cache数据量快速增长,进而推高显存压力、任务等待时间和整体推理成本。如何在性能、容量与成本之间取得更优平衡,正成为大 模型推理基础设施演进中的关键课题。
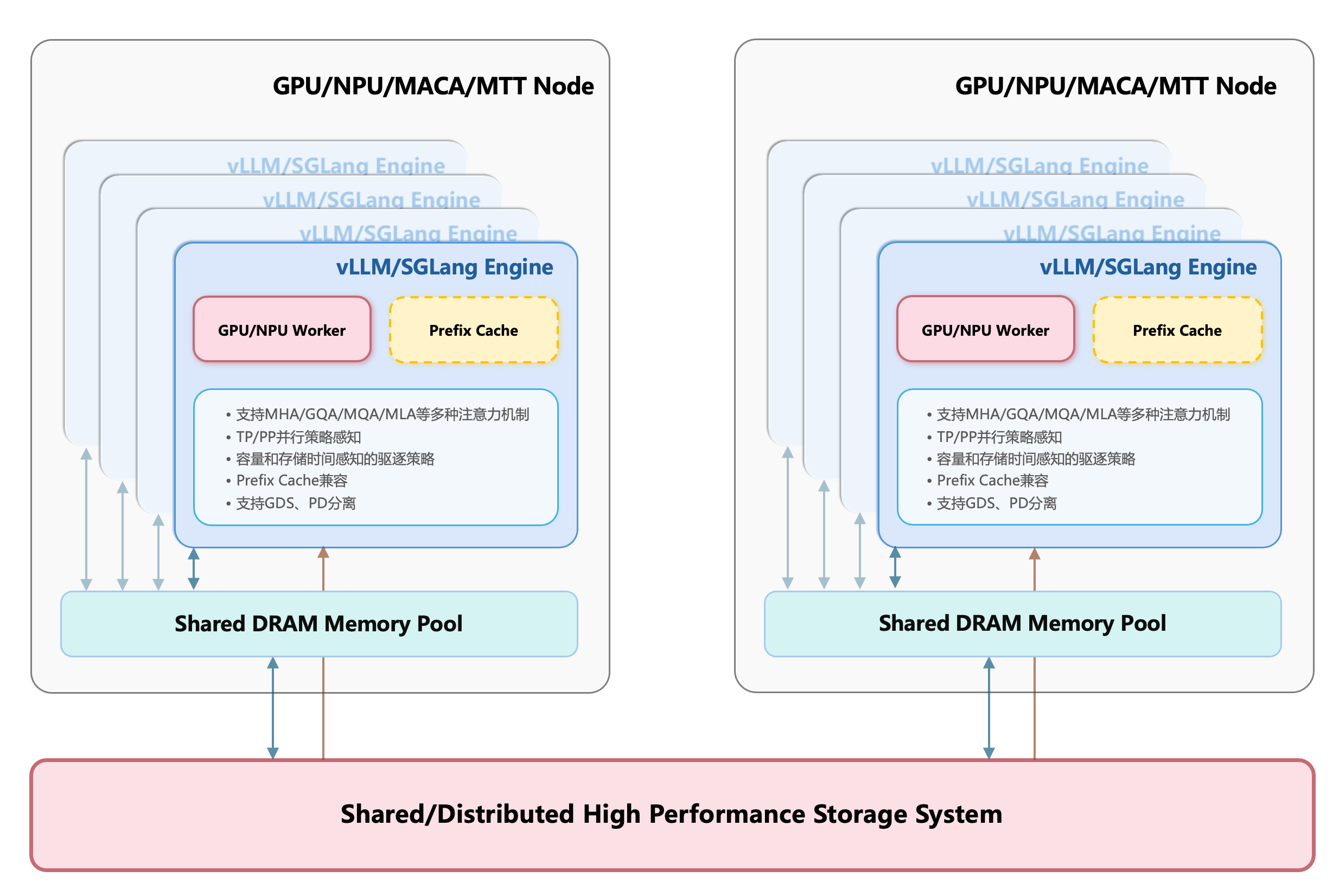
CT-HPKV(China Telecom High Performance Key Value Store)是中国电信天翼云自主研发的大模型推理多级KV Cache卸载系统,旨在扩展受限于显存 容量受限的PrefixCache能力,并将KV Cache的跨请求复用能力进一步扩展到CPU内存和高性能存储(SSD、HPFS等)。CT-HPKV突破了GPU显存瓶颈,显著扩 展了可承载的KV键值对规模与命中率,有效降低首token时延(TTFT),满足更高并发、更长上下文的推理需求,全面提升大模型推理的效率与响应能力。
HPKV的核心设计可概括为多级缓存链路:GPU HBM → Host DRAM → Local NVMe SSD/HPFS
GPU HBM:GPU显存,速度最快,适合承载当前最需要的热点数据;
Host DRAM:主机内存,可作为显存与更大容量存储之间的中间缓冲层;
Local NVMe SSD/HPFS:本地高速盘或远程高性能存储,容量更大,适合承载更大规模的缓存数据。
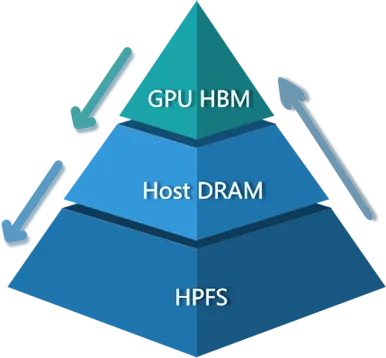
通过这样的分层设计,系统可将不同“温度”的数据放置在不同层级的资源上,在缓解显存压力的同时扩展缓存容量,为推理提速增效。
在此基础上,HPKV形成了缓存自动卸载、智能数据预取、分布式存储扩展及生态兼容等核心能力。从现有测试结果看,在长文本推 理场景下,首Token时延(TTFT)最高可降低85%;在任务排队阶段,通过智能预取,启动等待时间可缩短50%以上;在多轮对话场 景中,基于Qwen某千亿模型测试,HPKV平均命中率较vLLM提升4倍;在64并发高负载场景下,HPKV吞吐量达到vLLM的2倍,且 TTFT保持稳定。
应用场景#
长文本推理#
在论文理解、代码库解析、长文档问答等场景中,输入内容持续拉长,KV Cache会快速增长。HPKV通过将缓存卸载至Host内存以 及本地盘或远程存储,并在需要时快速调回,有效扩展系统对长上下文的承载能力,降低首Token时延,提升推理效率。
多轮对话#
随着会话轮次增加,历史上下文不断累积,若每轮都对已有内容重新计算,将带来较大资源消耗。HPKV通过高效的KV Cache复用机 制,对历史会话缓存进行保留和调用,以存代算,使系统能够将更多算力集中用于新增内容处理,减少重复计算开销。
海量请求#
在海量推理请求场景下,显存容量往往成为制约吞吐量提升的重要因素。HPKV通过将缓存数据迁移到更大容量的存储中,提高了KV Cache的命中率,更好地保障服务响应质量。
更多信息, 可参考如下链接:
CT-HPKV白皮书: https://docs.qq.com/doc/DUFd2UUxKbWZYd21k
CT-HPKV官方仓库: https://ctyun-code.srdcloud.cn/ZSJCSSZX/HPKV.git
功能特性
环境变量